ABBYY FineReader Express 8.4: распознавание текста с любых источников на лету (раздача кодов завершена)


Цифровой контент и электронные версии документов окружают нас со всех сторон. Для бумаги в нашей жизни почти не осталось места. Газеты и журналы перешли в онлайн-формат, книги мы читаем на e‑ink ридерах или планшетах, обычные письма заменили email и sms. Но все же, иногда нам приходится сначала повозиться с бумажками, чтобы получить их электронную копию. Здесь нам на помощь приходят специальные программы, которые используют технологию оптического распознавания текста OCR (Optical Character Recognition). Самой известной из них, бесспорно является ABBYY
FineReader. С ее помощью можно преобразовать бумажные документы в редактируемые форматы и сохранить PDF с возможностью поиска по тексту. И сегодня у нас есть отличная возможность познакомиться с ней поближе.
* * *
Для Mac’ов, ABBYY предлагает только FineReader Express, тем не менее она обладает необходимой функциональностью. Ключевыми особенностями ABBYY FineReader Express является точность распознавания и сохранение оформления, поддержка большого количества языков (171 язык, до трех языков в одном документе), преобразование и создание PDF (конвертация PDF в редактируемые форматы), редактор для ручной разметки областей (текст, таблица, картинка) и простой, удобный интерфейс программы.
Первый взгляд

Рабочее окно FineReader Express довольно минималистично, здесь присутствуют только самые необходимые элементы. В боковой панели располагаются эскизы добавленных страниц, а на панели иснтрументов кнопки с выпадающими списками: для выбора языка и выходного файла. Еще есть кнопки конвертации и масштабирования. В остальном, интерфейс соответствует быстрой экспресс-версии, в которой сделана ставка на автоматическое выполнение операций, с минимумом настроек и участия пользователя.
Переходим к испытаниям
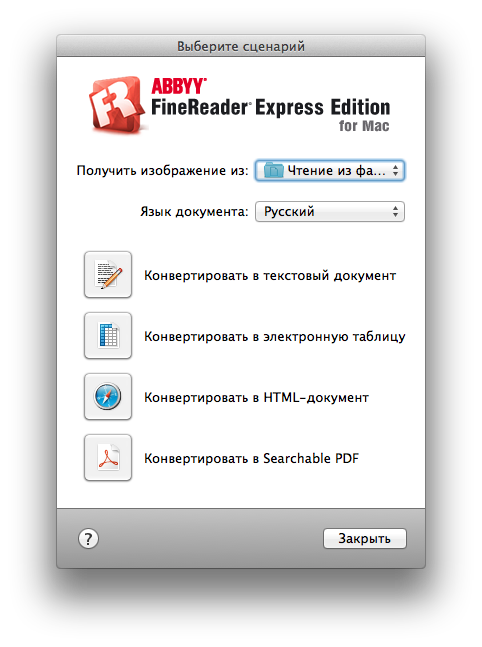
После запуска FineReader встречает нас компактным окошком с выбором сценария. Здесь нам предлагается выбрать источник захвата: сканер, факс или чтение из файла. Также рекомендуется указать язык документа (или языки, если их несколько) — это поможет улучшить точность распознавания исходного документа. Ну и собственно формат выходного файла, здесь все просто — выбираем, исходя из типа бумажного документа.
Сканера под рукой у меня не оказалось, но это даже к лучшему — используя в качестве источника фото сделаные с помощью iPhone, я усложнил задачу по распознаванию текста. В качестве примера текста я взял одну из книжек своей супруги, а в качестве примера таблицы — какую-то старую рабочую накладную из фотопленки айфона. Что ж, давайте приступим.
Распознаем страницу с текстом
За неимением сканера я просто сделал фото разворота книги — обычное фото при комнатном освещении, никаких штативов и прочих ухищрений. Вот оригинал:

Посмотрим, что с ним сможет сделать FineReader. Указываем, что хотим вытащить из фото текст, определяем язык как русский и запускаем процесс.

К чести приложения нужно сказать, что определился весь текст, включая случайно попавший с изгиба соседней страницы. Кусок стола, который я специально оставил в кадре, ожидаемо определился как картинка. Но это не страшно, так как мы можем вручную изменить области определения, указать их тип (если программа определит неверно) и удалить области, распознавание которых не требуется. Все манипуляции заняли у меня меньше минуты, а в итоге я получил вот такой, вполне приемлемый результат:

После небольшой вычитки и правки документ готов. Я считаю, что это достойный результат для такого быстрого, почти автоматического процесса распознавания.
Распознаем таблицу

В качестве подопытной таблицы выступает простенькая накладная, которая тоже была снята на айфон. Здесь уже используется украинский (заодно и проверим поддержку языков), что тоже полезно для нашего опыта. Выбираем новый сценарий (⌘N) указываем источник — чтение из файла, язык — украинский и файл на выходе — таблица.
Программа задумывается на несколько секунд и вот перед нами результат:

С таблицей программа справилась не так хорошо, но в принципе определение текста более-менее сносное, разве что почему дорисовались ячейки, которых не было в исходном документе. Тут придется повозиться немножко дольше, чтобы добиться финального вида отображения документа, но все же это проще чем набирать табличку с вручную с нуля.
Сохранение в PDF

При сохранении в PDF, к сожалению программа никак не улучшает исходное изображение (контраст, яркость) и оно помещается в PDF-документ как есть. Но тем менее, поиск по тексту присутствует, а это уже хорошо.
Итог
Как и любой инструмент, FineReader имеет свои плюсы и минусы. К сильным сторонам, помимо заявленных производителем характеристик, является то, что распознавание текста и таблиц работает достаточно неплохо, а конвертирование в PDF, как и обещано, поддерживает поиск по тексту. Минусом можно считать отсутствие настроек и очень скудные возможности по ручному управлению процессом. Но это отчасти оправдывается, тем что это экспресс-версия и работает она в автоматическом режиме.
Коды для программы FineReader Express выиграли Григорий Ушаров и Николай Блинов. Поздравляем! Проверяйте личные сообщения, коды отправлены.













Мас-рестлинг, хуреш и ещё 5 необычных национальных видов спорта России
5 способов успокоиться, если вы переживаете за экзамены ребёнка сильнее, чем он сам
На что влияет сахар в крови? Отделяем мифы от фактов
Безопасные покупки: как Ozon бережёт вас от мошенников
Реклама